单次支持38万字输入!腾讯混元推出256k长文模型,通过腾讯云向企
|
AI大模型技术正成为推动高质生产力发展的关键力量,在与千行百业的融合中发挥着重要作用。腾讯混元大模型通过采用混合专家模型 (MoE) 结构,已将模型扩展至万亿级参数规模,增加脑容量提升预测性能的同时,推动了推理成本下降。作为通用模型,腾讯混元在中文表现上处于业界领先水平,尤其在文本生成、数理逻辑和多轮对话中性能表现卓越。 近日,腾讯混元大模型正式对外发布256k长文模型,并通过腾讯云向广大企业和个人开发者开放,以支持更广泛的创新和应用。腾讯混元256k模型版本具备处理超过38万字符的超长文本能力。在对话应用场景中,该模型能够记忆更多的对话内容,有效避免忘记信息等问题。此外,它还具备出色的上下文分析能力,能够为对话参与者提供更为精确和相关的反馈,从而辅助他们做出更明智的决策。 此外,该模型版本在长文档的阅读理解和大规模数据分析方面也展现出强大性能。它能够为金融、医疗、教育、出行等行业的专业人士提供强有力的工作支持,显著提高他们的工作效率。模型在推理性能上也进行了深入优化,确保了在腾讯云等平台上的实际应用中,用户能够享受到更加流畅和高效的使用体验。 减少健忘,让大模型更聪明 在大模型产品中,处理对话式需求是一项核心功能。但由于长文本处理能力的局限,传统大模型在对话中容易迷失方向或出现记忆缺失,随着对话长度的增加,遗忘的信息量也随之增多。 腾讯混元256k模型针对这一挑战进行了专门优化。它采用了先进的专家混合(MoE)架构,并融合了RoPE-NTK和Flash Attention V2等创新技术,既保持了对通用短文本(少于4,000字符)的高效处理能力,同时在长文本处理的深度和广度上实现了突破。 目前,腾讯混元大模型已经具备256k的超长上下文理解能力,单次处理字符数超过38万个,在经过严苛的大海捞针任务测试后,该模型在长文本处理上的准确率已达到99.99%,在国际上也处于领先地位。 持续稳定迭代,大模型应用效率提升 腾讯混元大模型在业界率先采用了混合专家模型(MoE)结构,并在此过程中积累了大量自研技术。在上一个版本32K中,该模型已显著超越市面上的开源同类模型,并在多种应用场景中展现出优异性能。 经过全新迭代,腾讯混元256k在通用领域的GSB评测中,相较于前一版本,胜出率50.72%。同时,腾讯混元256k的训练集融合了医疗、金融等多个领域的长文本数据、翻译数据和多文档问答等高质量标注数据,这使得模型在实际应用中,尤其是在需要频繁分析和处理大量长文本资料的医疗和金融行业,能够提供更为精准和高效的工作支持。 例如,当将一份央行发布的金融报告输入腾讯混元256k模型时,该模型能够迅速提炼和总结报告的要点,在处理速度和准确性上均达到了令人满意的水平。
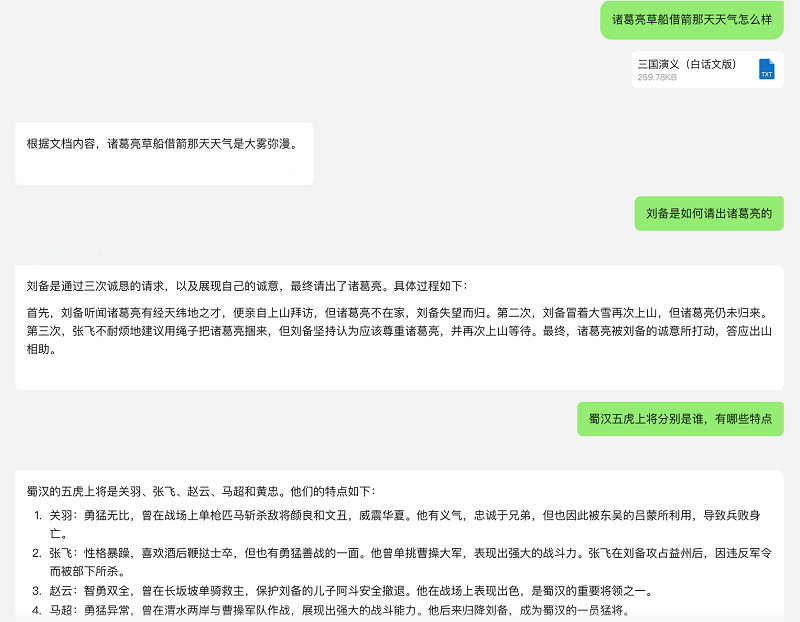
推理性能优化,带来更强的大模型理解能力 与此同时,腾讯混元256k在推理性能上进行了深入优化。在INT8精度模式下,与FP16精度相比,模型的QPM(每秒查询率)实现了23.9%的显著提升,而首字耗时仅增加了5.7%。这些改进显著增强了模型在实际应用中的响应速度和整体效率。 以《三国演义》的分析为例,腾讯混元256k能够迅速阅读并检索这部数十万字的古典小说,不仅能够准确识别出小说中的关键人物和事件情节,甚至对于天气、角色着装等细节描述也能提供精确的信息。
AI大模型作为新质生产力的关键组成部分,对推动产业升级和实现高质量发展具有至关重要的作用。腾讯混元256k模型的推出为整个行业注入了全新活力,并开拓了更广泛的应用前景。 目前,腾讯混元256k长文模型已经通过腾讯云向广大企业和个人开发者开放,用户可通过hunyuan-standard版本256k长文模型接入。这使得更多的开发者和用户能够便捷地接入并使用腾讯混元大模型的强大功能,进而为各行各业提供智能化的解决方案,推动更多创新应用场景的实现。 |